Słowem wstępu
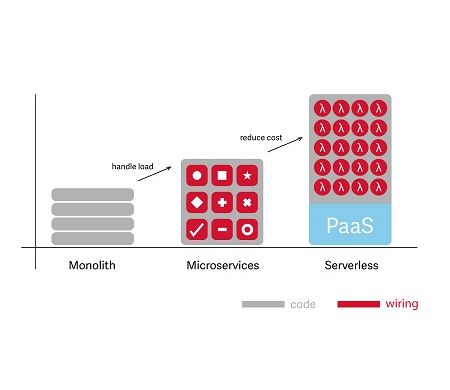
Monolit – docker – serverless.
W bardzo dużym skrócie można powiedzieć, że wiele zespołów developerskich podąża tą drogą. Trochę taka jest również historia rozwoju naszego oprogramowania.
Wiele lat spędzonych nad „rozwojem” monolitu, dało nam w kość, jak u wielu innych przekonaliśmy się, że podążając tropem tego rozwiązania, nieuchronnie docieramy do ściany. Okazało się, że mnogość integracji jakie wykonaliśmy powoduje, że drobna zmiana staje się nieznośnie czasochłonna dla biznesu jak i niezwykle uciążliwa dla developerów oraz wdrożeniowców. Do tego przy każdej kolejnej zmianie potęguje się ryzyko „popsucia” czegoś.
Nieco dla zobrazowania monolitu trochę humorystycznie napiszę, że była to ogromna kanapka wielowarstwowa, z której odchodziła ogromna liczba macek spaghetti realizujących różnorodne integracje, do tego dochodził cache a następnie frontend który synchronicznie musiał się zmieniać razem z kanapką 😊
Dziś jesteśmy bardzo szczęśliwi, że „KTOŚ” 😊 (Solomon Hykes i Sebastien Pahla) wymyślił Dokera, a my znaleźliśmy odwagę aby podjąć się wyzwania „rozbicia” monolitu. Pół roku intensywnej pracy ZESPOŁU dało nam spory przyczółek w postaci nowego środowiska kontenerowego obejmującego główne funkcje monolitu. Po początkowej niepewności związanej z wchodzeniem na nieznany grunt okazało się, że developerzy .NET znakomicie radzą sobie z planowaniem nowej architektury dockerowej. Okazało się, że podział na domeny dockeryzacji nie jest taki trudny i po pewnym czasie cięcie tego ciastka na mniejsze kawałki stało się dla wszystkich oczywiste i jasne.
W tym miejscu należy napisać jakie główne korzyści osiągnęliśmy :
- Prostota wdrożeń – użyliśmy chmury AWS (oczywiście można dowolnej innej), początkowo ręcznie robiona zmiana numeru obrazu pobieranego z DockerHuba. Tak - i na tym koniec. Bez żmudnych instrukcji wdrożeniowych, nocnych wgrywek , angażowania wielu osób.
- Automatyzacja wdrożeń – użyliśmy Azure DevOps Pipelines, kolejnego "pięknego" narzędzia ułatwiającego życie gdzie po każdym commicie do mastera można zrobić ścieżkę automatycznych testów oraz wdrożenie na kolejne środowiska TEST, STG, PROD.
- Ułatwienie testowania nowych funkcjonalności ze względu na fakt, że te już zdockeryzowane przestały wpływać regresyjnie na pozostały monolit.
- Możliwość pisania kodu w różnych językach programowania, poprzednio byliśmy skazani na .NET, docker znosi to ograniczenie, możemy używać np. Golang, gdzie kontenery są mniejsze i wydajniejsze.
- Podniesienie kompetencji zespołu develperskiego w kierunku do DevOps. To należy szczególnie docenić, biorąc pod uwagę indywidualną chęć rozwoju każdego developera.
Słowem rozwinięcia
Choć nie zdążyliśmy jeszcze wykorzystać wszystkich możliwości, które daje nam dockeryzacja, coraz silniej zaczęły się już przebijać głosy: "Dlaczego nie Serverless?"
Zapaliła się żarówka, zarówno w głowach DevOps’ów jak i managerów. Dev mówi : _„Dlaczego nie pisać prostych , małych i szybkich i bezstanowych funkcji ? Po co my mamy w ogóle gadać z Opsami?”
Manager mówi : „Po co nam tak duże koszty chmury ?”.
W tym momencie skupmy się na konktretach. Przetwarzanie bezserwerowe oczywiście z serwerów korzysta ale nie bezpośrednio . Dostawcy chmurowi AWS, Amazon, Google oferują usługę FaaS (Function as a Service). Usługa ta umożliwia programiście napisanie bezstanowej funkcji i wgranie jest bezpośrednio do FaaS.
Co to jest funkcja ?
Dokładnie rzecz biorąc programista piszę taki taki kod, jakiego potrzebuje, w wybranym przez siebie języku i osadza go w szkielecie funkcji. Ten szkielet to nic innego tylko runtime, który zawiera zestaw niezbędnych bibliotek uruchomieniowych odpowiednich dla języka (Pyton, Java, Node.js, .NET). Oprócz tego pakiet zawiera definicję wyzwalacza, zabezpieczenia oraz ew. parametry uruchomieniowe.
Istotną rzeczą jest tu wyzwalacz, czyli zdarzenie które uruchomi i wywoła funkcję. Najczęściej jest to żądanie http (np. Rest API), które uruchomi kontener zawierający funkcje. Funkcja uruchomi się wykona zadanie np. zapisze jakieś dane w bazie albo wyśle PUSH do aplikacji mobilnej klienta itp. Po czym kontener z funkcją pozostanie jeszcze przez pewien czas uruchomiony gdyby trzeba było obsłużyć kolejne żądania, następnie zostanie zamknięty.
I teraz główne zalety :
- platformy FaaS umożliwiają bardzo szybkie **autoskalowanie**, dzięki czemu nie mamy problemu z wydajnością.
- obniżamy koszty w stosunku do kosztów „klasycznych-zdockeryzowanych” chmur. W tym modelu płacimy często tylko za czas i ilość żadań.
Tu cytat ze strony AWS :
With AWS Lambda, you pay only for what you use. You are charged based
on the number of requests for your functions and the duration, the
time it takes for your code to execute.
Wygląda to optymistycznie ale UWAGA! w praktyce gdybyśmy zbudowali funkcję realizującą długotrwały proces może okazać się, że koszty będą wyższe niż przy klasycznym podejściu.
- Programujemy bez zastanawiania się nad infrastrukturą (czy Administratorzy nie są już potrzebni ? 😊)
- Małe funkcje można bardzo szybko wdrażać i aktualizować
- Ponieważ funkcje nie są przypisane do serwerów , bardzo łatwo je przenosić i uruchamiać np. sieciowo bliżej klienta. Wyobraźmy sobie, że uruchamiamy usługę biznesową w USA i w Niemczech.
I teraz oczywiście wady :
Jest coś takiego jak Cold Start. Oznacza to, że kontener zawierający funkcję potrzebuje trochę czasu aby się uruchomić. Czas ten jest zależny od platformy dostawcy oraz od wielkości samej funkcji, dlatego ważne jest aby były one niewielkie. Niektórzy twierdzą, że można to obchodzić przez „cykliczne wywołania”, coś w podobieństwie do rozgrzewania cache, natomiast natomiast decydując się na taki zabieg, zatraca się poniekąd idea Serverless. Ten temat jednak omówimy dokładniej w osobnym wpisie.
- Musimy zdawać sobie sprawę, że debugowanie jest większym wyzwaniem, ponieważ cała aplikacja jest podzielona na mniejsze funkcje odseparowane od siebie.
- Dochodzą wyzwania bezpieczeństwa, ponieważ przy np. przetwarzaniu danych związanych z RODO może się zdarzyć że „pod spodem” na tej samej infrastrukturze uruchamiane są funkcje różnych klientów, co potencjalnie przy błędnej konfiguracji może powodować ujawnienie danych.
- W aplikacji Serverless ciężko realizuje się komunikację w czasie rzeczywistym np. WebSocket, choć nie jest to niemożliwe.
Kto powinien korzystać z architektury bezserwerowej?
Programiści, którzy chcą skrócić czas wprowadzania produktów na rynek i tworzyć lekkie, elastyczne aplikacje, które można szybko rozbudowywać lub aktualizować.
Podejście serverless zmniejsza koszty aplikacji, które wykazują duże fluktuacje ruchu, dla przykładu w aplikacjach gdzie klienci masowo reagują na moment promocji lub konkursu zaś poza tymi okresami, ich ruch jest niewielki. W takich wypadkach nie ponosimy kosztów bezczynności aplikacji.
Ponadto z architektury bezserwerowej korzystać mogą programiści, którzy chcą przesunąć niektóre lub wszystkie swoje funkcje aplikacji blisko użytkowników końcowych w celu zmniejszenia opóźnień.

.jpg)
.png)